기본적으로 ElasticSearch를 사용하기 위해서는 어디에선가 데이터를 가져와 집어넣어야 한다.
가장 원론적인 방식은 일일이 데이터를 손으로 입력하는 방식이겠지만 사실 이 방식은 말이 안된다.
그래서 일반적으로 Logstash를 파이프라인으로 이용하는데 아래 그림과 같다.
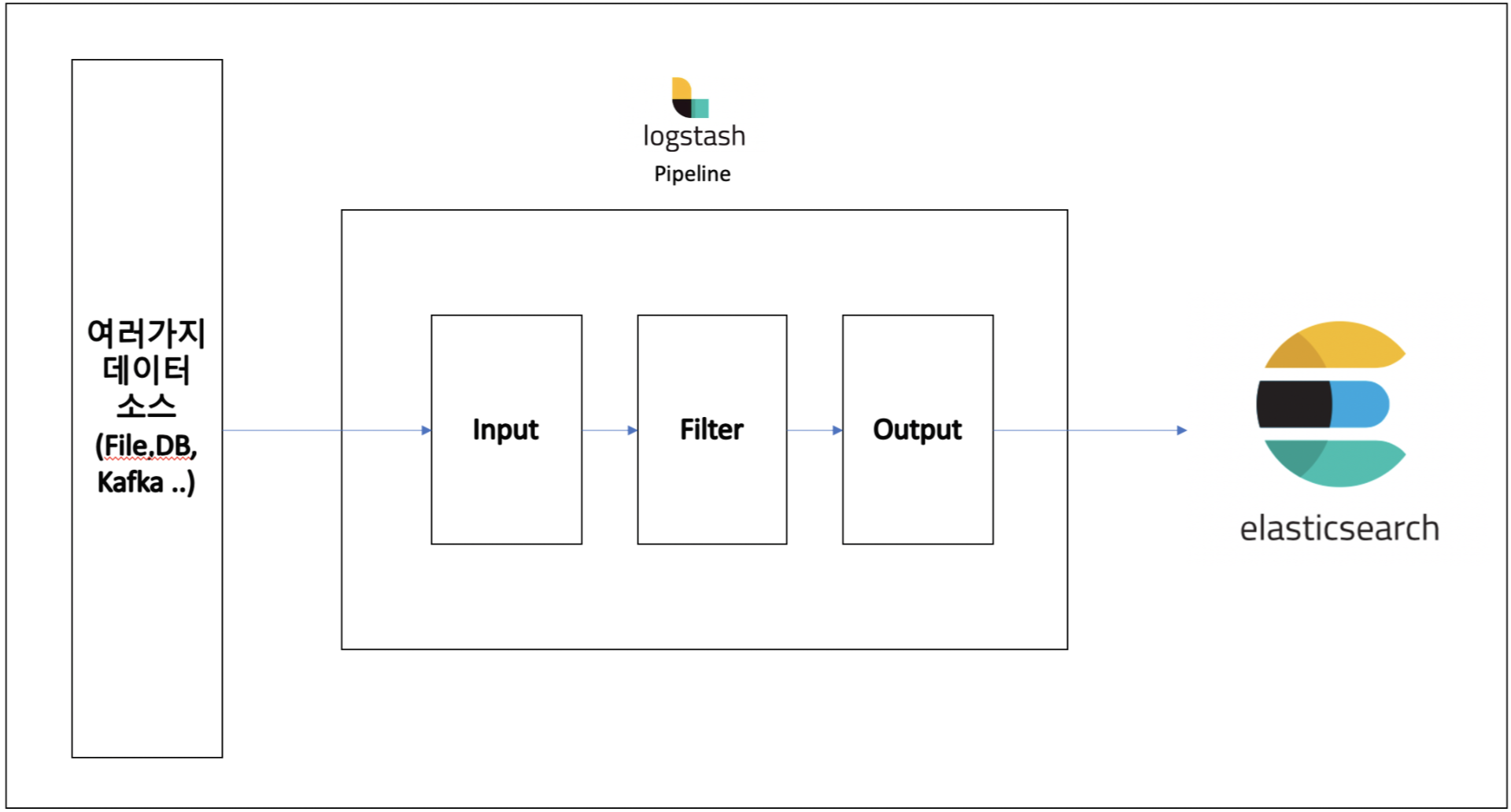
여러가지 데이터 소스가 존재하는데 CSV파일에서 가져올수도 있고 Mysql, Kafka등 굉장히 여러가지 소스가 있다.
아무튼....설치 하는 과정은 지나가도록 하고 pipeline을 만들어주기 위한 logstash 설정법을 설명하겠다.
당연히 elastisearch와 logstash를 하기 위해서는 JAVA가 깔려있어야 하고 Mysql이 설치되어 있어야 한다.
그리고 설정파일을 작성해줘야 한다.
지금은 Ubuntu를 기준으로 설정한다. 로그스테시를 설치하고 systemd에 설정을 완료하고 /etc/logstash에 파일들을 저장되어 있을텐데
파일 제목은 알아서 정하지만 확장자명은 .conf로 설정한다.
안에 파일내용은 다음과 같다.
input{
jdbc{
jdbc_driver_library => "/lib/mysql-connector-java-8.0.18.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/logstash?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "root"
statement => "SELECT title,contents FROM board"
schedule => "* * * * *"
}
}
#filter{
# mutate{
# copy => {"title" => "[@metadata][_id]"}
# }
#}
output{
elasticsearch{
hosts => "http://127.0.0.1:9200"
codec => "json"
index => "x_test"
# document_id => "%{[@metadata][_id]}"
}
}
mysql을 연결하기 위해서는 mysql-connector가 필요한데, "mysql-connector-java-8.0.18.jar" 이부분이 connector를 저장한 위치를 작성해주면 된다.
https://dev.mysql.com/downloads/connector/j/
MySQL :: Download Connector/J
MySQL Connector/J 8.0 is highly recommended for use with MySQL Server 8.0, 5.7 and 5.6. Please upgrade to MySQL Connector/J 8.0.
dev.mysql.com
여기서 다운으면 된다.
그 후 Spring에서 Mysql 연결 하는 것과 동일하게 작성해준다.
원하는 쿼리문을 작성하고 스케줄을 정해준다.
밑에 filter를 통해서 원하는 형식으로 파싱을 해주고
output에서 elasticsearch로 보내준다. index는 데이터 저장공간을 의마한다.
이렇게 설정해준 이후 pipeline.yml
- pipeline.id: main
path.config: "/etc/logstash/logstash.conf"설정 파일을 작성해준다. 여러개일경우 여러개를 작성해준다.
그리고 systemctl start logstash 이미 시작한경우 systemctl restart logstash로 실행해준다.
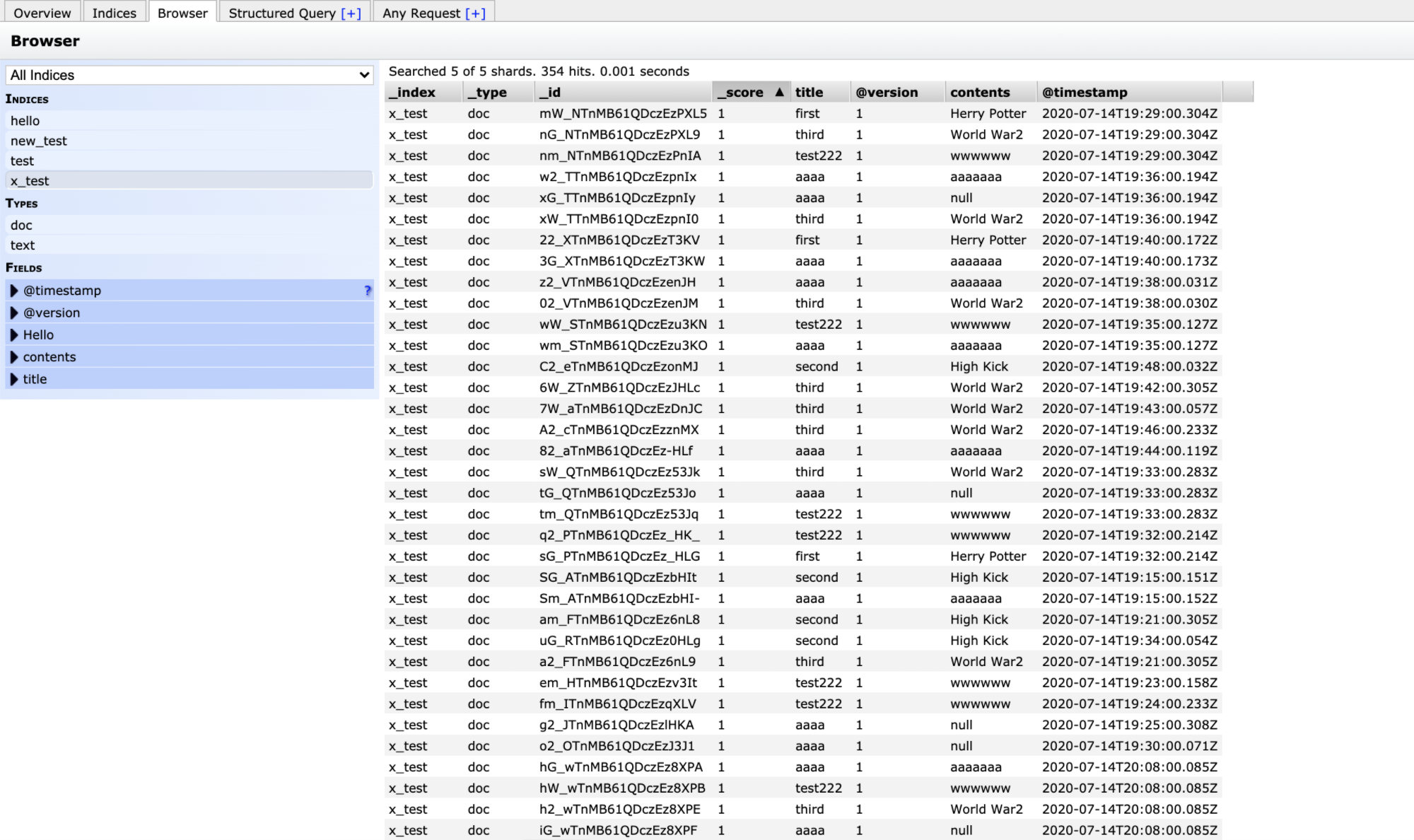
그러면 mysql에 있는 데이터가 잘 들어가는 것을 확인 할 수 있다.
'ELK' 카테고리의 다른 글
| Elasticsearch를 이용한 문서 유사도 검색과 Springboot를 통한 구현 (1) (0) | 2020.09.05 |
|---|---|
| logstash deactivating (stop-sigterm) 해결방법 (0) | 2020.09.04 |
| elasticsearch java high level rest client에서 analyze 사용 (0) | 2020.08.05 |
| Elasticsearch Type에 대해서 (0) | 2020.07.27 |
| Elasticsearch spring REST Client unrecognized parameter 오류 (0) | 2020.07.22 |
